
 We have made an ‘audience level’ service available as a prototype. This is available as a human interface, a web service, and as greasemonkey scripts which insert an audience level in an Amazon or Open WorldCat page based on interaction with the web service.
We have made an ‘audience level’ service available as a prototype. This is available as a human interface, a web service, and as greasemonkey scripts which insert an audience level in an Amazon or Open WorldCat page based on interaction with the web service.
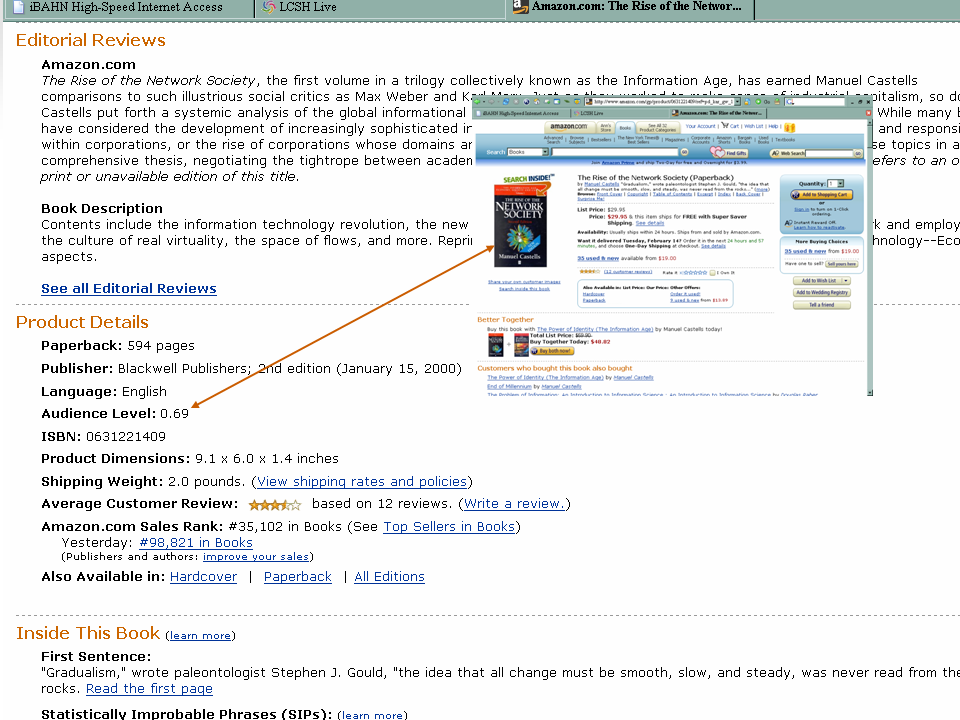
This service is based on the insight that we can say something about the likely audience for an item based on its pattern of distribution across libraries (WorldCat knows about over a billion items available from thousands of libraries). So, for example, if something is held by several research libraries it is likely to be of specialized interest; if something is held by several thousand public libraries it is likely to be of general interest. Read more about it on the ResearchWorks website:
This prototype system, developed in conjunction with the Audience Level research project, uses library holdings data in WorldCat to calculate audience levels for books represented in the WorldCat database, based on the types of libraries that hold the titles. [About the Audience Level prototype [OCLC – ResearchWorks]]
What this service does is give a ‘hint’ or a ‘suggestion’ about an item: it is not necessarily definitive, but is often useful. It is an example of a service that might belong in the ‘texture of suggestion‘ I talk about in the context of Amazon. One might also use it to filter when creating reading lists or bibliographies, for example. We have been very pleased at the ways in which xISBN has been used, and we look forward to seeing what creative uses people might have for this.
I really like audience level and xISBN as they are examples of higher level services which can be provided on the basis of mining large data aggregations. As a community, we need to make our data work harder in this way.


